OSDI2018:探寻计算机系统之美

Symposium on Operating Systems Design and Implementation(操作系统设计与实现,后简称 OSDI)是计算机系统设计的顶级会议,由 USENIX 主办,两年一届。OSDI 作为系统研究领域的最高级别学术会议,镌刻下了计算机科学家们智慧的闪光和对计算机系统的前瞻性思考。诞生在 OSDI 上的大量工作,比如 MapReduce、BigTable 等,深刻的影响了整个互联网的发展。

微软力量闪耀 OSDI
本届 OSDI 会议共吸引了 1300+ 作者的 257 篇投稿,录用论文 47 篇,录用率 18%。微软作为大会的主要赞助商之一,创纪录地有 12 篇论文被录用,占大会总文章数的 1⁄4 以上,发表量稳居第一。本届大会共评选出 3 篇 Best Paper,其中两篇来自微软。

此次 OSDI 还为微软亚洲研究院院友们提供了一次交流机会,大家在南加州留下了这张珍贵的合影,庆祝 MSRA 成立 20 周年。MSRA 副院长周礼栋博士(前排右三)、张霖涛博士、杨凡博士、张权路博士等多名系统组研究员参加了本次大会。大家与多位院友相聚一堂,包括在这次大会上一口气发表 4 篇文章的 MIT 教授 Frans Kaashoek,不久前刚来 MSRA 进行讲座的 ACM 和 IEEE Fellow Lorenzo Alvisi 教授,还有美国顶级名校的年轻老师们 Xi Wang,Yiying Zhang,Peng Huang等。
大会速递:系统质量与计算系统成为 OSDI 的焦点
此次 OSDI 的47 篇文章涵盖了计算机系统的方方面面。在大的文章分类上,OSDI 还是一如既往地关注系统质量相关的研究,错误分析、Debug、形式化验证、安全等相关内容的研究占比超过 1/3,还贡献了两篇最佳论文。另外,今年也有不少文章讨论面向应用的计算系统设计,特别是机器学习相关系统研究,在今年的 OSDI 上迎来了一个爆发。
系统质量
在一个复杂分布式系统中,很多情况下系统尚未崩溃,甚至基于一些心跳机制的系统健康性汇报还呈现正常状态,但是系统的部分功能已经丧失,这种介于正常和失效间的状态被 Peng Huang 等人定义为 Gray Failure。针对这样一个新概念,他们提出了 Panorama,通过静态代码分析,在原有程序出错处理的地方插入相应的信息汇报代码,进而在运行时通过一个中心分析节点来综合汇报故障信息,从而找到这种难以被发现的 Gray Failure。
论文链接 https://www.usenix.org/conference/osdi18/presentation/huang
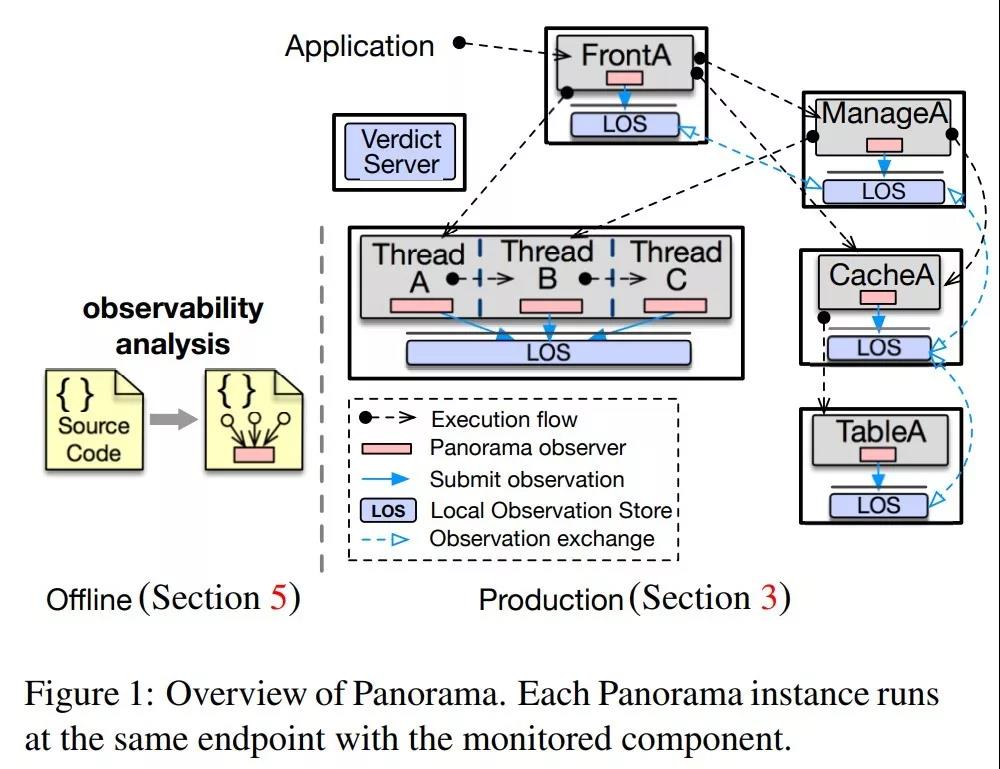
与 Panorama 专注于定位错误不同,微软的 Best Paper展示了一个已经部署在 Windows 系统中的 Debug工具 REPT,可以在错误发生的时候,帮助开发人员从 Core Dump 恢复执行时的寄存器和内存状态,进而知道整个执行的过程,理解错误产生的原因。REPT 的前后向扫描推测技术,可以基于汇编代码推断出执行时的状态。而对于多线程场景,REPT 利用了硬件提供的时间戳来确定执行的序列,从而帮助执行时状态的推测。在 OSDI 的论文展示现场,REPT 还在 Visual Studio 上进行了现场 Demo,相信这一实用技术很快就能被更多的人用上。
论文链接 https://www.usenix.org/conference/osdi18/presentation/weidong
微软的另一篇 Best Paper——Orca,则关注软件工程过程中持续提交带来的 Bug,旨在帮助 On-call 工程师定位 Bug,减少服务中断的时间,也是非常实用、接地气的一个话题。系统通过代码分析和关键词匹配,代码提交图追踪,和基于机器学习的评级算法来推断引入 Bug的代码提交位置。最终,Orca 能做到 77% 的准确度,减少3倍工程师的工作量。
论文链接 https://www.usenix.org/conference/osdi18/presentation/bhagwan
Graviton 是微软等单位带来的关注安全性的工作。与以往关注 CPU 端安全性的工作不同(比如说Intel的SGX和ARM的Trustzone),这个工作关注了 GPU,指出 GPU 上提供可信执行环境也非常的重要。GPU 的设计之初就缺乏可信原语,这给很多共享环境下的 GPU 程序攻击提供了可乘之机。一般 GPU 上执行的都是计算密集型的任务,这篇文章希望能在尽量不损害 GPU 的使用性能的情况下,为 GPU 计算提供安全性的支持。这个工作主要提出了一个 Secure Channel 抽象来保护 GPU 内存,并采用密钥机制保护数据和代码,其具体实现还需要修改 CUDA Runtime、驱动和硬件。
论文链接 https://www.usenix.org/conference/osdi18/presentation/volos

计算系统
深度学习毫无疑问是当下系统届最关注的应用之一,以至于在一些系统设计的文章中被当作重要的 Benchmark,这次 OSDI 的 Best Paper——LegoOS 就使用深度学习 Benchmark 来佐证 Resource Disaggregation 的实用性。无独有偶,普渡和斯坦福联合出品的 Flare 也用深度学习应用来展示对于 Spark 的优化效果。
论文链接 https://www.usenix.org/conference/osdi18/presentation/shan
去年 SOSP 上几乎没有相关系统设计的文章。在沉寂一年之后,深度学习系统在今年的 OSDI 上再度亮相。OSDI2018 专门设置了机器学习的 Session,一共录取了 4 篇文章,分别讨论了机器学习系统的四个重要的问题:1. 针对新型机器学习应用的系统设计; 2. 深度学习程序在异构硬件上全自动编译器设计;3. 深度学习计算资源平台的设计;4. 机器学习模型服务部署上的优化。
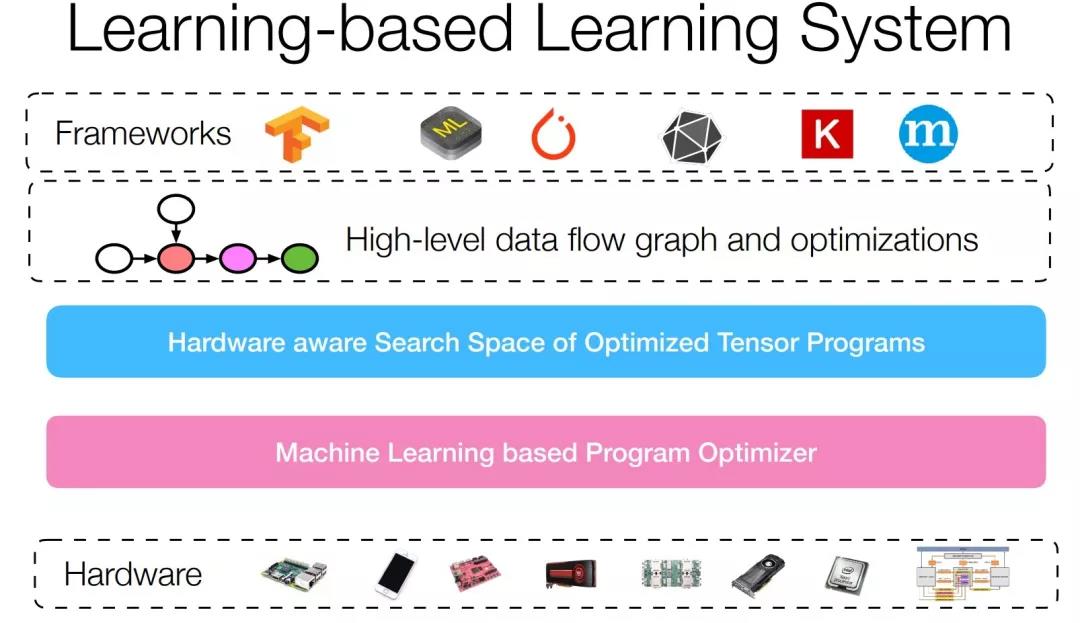
TVM 是华盛顿大学陈天奇等人打造的全自动深度学习编译器,希望能支持异构硬件上的自动代码生成和优化。在我看来,这是深度学习走向实用和异构硬件飞速发展的今天非常迫切的现实需求,也非常具有挑战:如何把传统的编译技术和全新的应用、异构的硬件特性做一个好的抽象整合,非常考验系统设计的能力。整个 TVM 的系统抽象将 Framework 到硬件的代码生成优化分成了三个部分:高层数据流图优化、考虑硬件特性的代码生成搜索空间表达、以及基于机器学习的代码优化器。TVM 展示了其自动代码生成对于现在已经广泛使用的GPU 有加速的效果,并且在比较冷门的 ARM CPU 和 GPU 甚至 FPGA 上,也都能获得生成高质量的代码,进而极大程度节约了工程师的工作量。
论文链接 https://www.usenix.org/conference/osdi18/presentation/chen
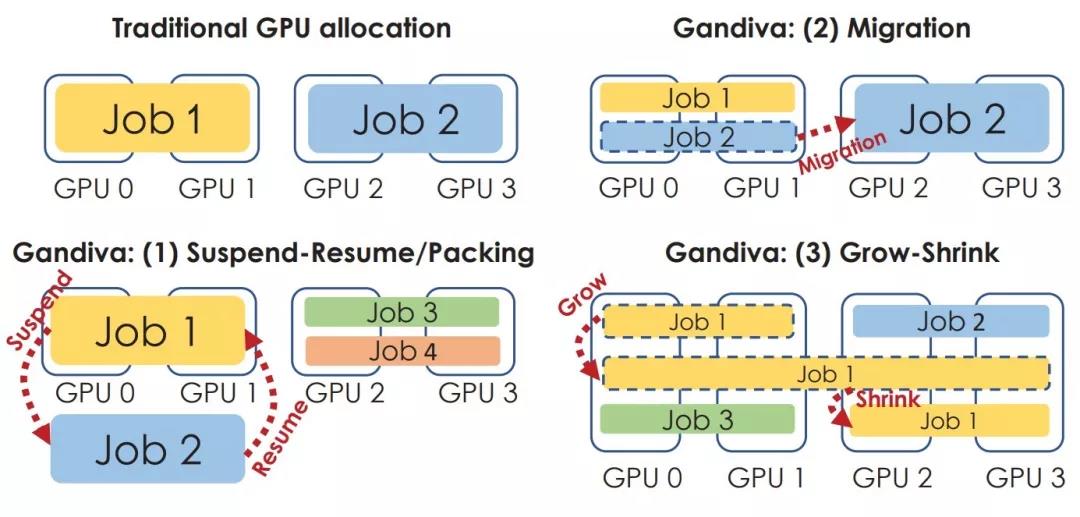
Gandiva 是我们基于对于微软内部深度学习训练平台的观察和思考,进而提出的全新深度学习平台调度系统。深度学习任务不同于大数据任务,它是一个面向研究员用户的反馈驱动的学习过程。用户往往为了一个特定的目标在特定数据集上做着模型结构或者参数的搜索(如手动的调参或自动化的 AutoML),而达到这个目标通常需要一系列的任务来寻找那个最佳的模型。于是,优化其中的某个特定任务,很多时候在整个流程中显得并不是那么的重要,相反,机器学习训练的收敛特性使获得尽早提供反馈往往能加速整个搜索的过程。
另外一方面,不同深度学习模型在资源需求上呈现异构性,对于一些任务来说,运行在不同的计算资源上往往带来巨大的执行效率差别,集群资源调度器很难在一开始为一个任务找到最佳 GPU 资源位置。区别于传统集群调度器把一个任务当作黑盒,仅在任务提交的时候做单次调度,Gandiva 利用了深度学习任务的周期性特性,按需将多个 Minibatch 作为一个调度的粒度,通过观察和获取运行时的任务特性和数据来进行“内省”调度,从而可以显著降低深度学习整个 Pipeline 的时间,并且提升整个GPU集群的资源利用率。在 Gandiva 中,我们提供了一系列全新的调度机制:Packing, Time-slicing, Migration, Grow-shrink 等,允许多个深度学习任务同时或者分时地运行在一组 GPU 之上,也允许运行时的任务在不同的机器间迁移调整等。这些全新的机制结合在一起使得 Gandiva 可以提升 26% 的集群资源利用率,并且带来 10 倍以上的 AutoML 加速。
论文链接 https://www.usenix.org/conference/osdi18/presentation/xiao
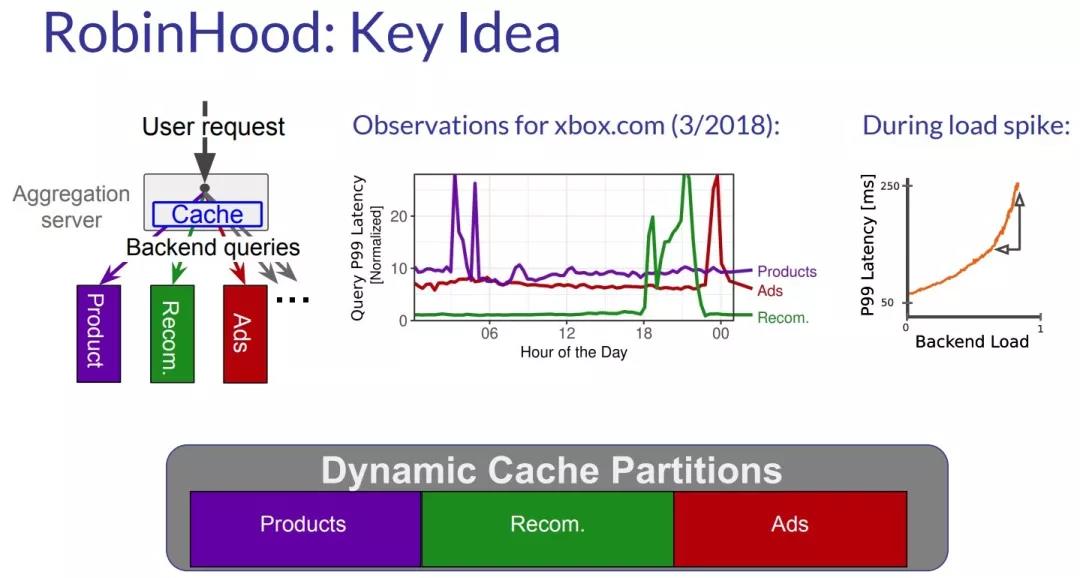
与 Gandiva 一样,RobinHood 也从一个全局性的思路去考虑一个缓存系统设计的问题。以往,研究员们都认为缓存并不能优化系统的 Tail Latency,而作者观察到这样一件事情,一个复杂系统的缓存(Cache)背后通常是一系列的独立的服务,一个请求的延迟是这些服务延迟的最大值,而这些服务的 Tail Latency 在不同时期是不一样的。基于这个发现,他提出 RobinHood 这个工作,Idea 也很直观而讨巧,即动态的对于 Cache 进行划分,对于 Tail Latency 大的那些服务就给它分配更大的 Cache,这样就可以优化整体系统的 Tail Latency。
论文链接 https://www.usenix.org/conference/osdi18/presentation/berger
Flare 是传统大数据系统相关的工作,针对 Spark 在中等规模数据处理场景下做优化,由斯坦福和普渡联合完成。Spark 作为大数据基础设施,在工业应用中可谓必不可少,而针对 Spark 的性能分析的文章从未停止过。
论文链接 https://www.usenix.org/conference/osdi18/presentation/essertel
早在 2015 年,Kay 的 NSDI 文章指出 IO 或者说网络很多时候并不是瓶颈所在,一时让人大跌眼镜。Flare 也指出 Spark 在处理中等规模数据上的性能问题,需要引入不一样的系统设计,这其实跟 Frank McSherry 在 COST 文章中关于 Efficiency 和 Scalability 的讨论相呼应。Flare 分析了 Spark 处理中等规模数据的性能,找到了三个瓶颈所在,并针对性地优化:将查询编译为 Native Code 来避免胶水代码和 JVM 带来的额外开销,而查询也针对实际场景进行编译优化,绕过 Spark 针对分布式执行的过度优化。这个工作恰恰说明了从系统设计的角度来讲,系统设计的时候往往有潜在的关于应用场景和底层依赖的假设,不可能适用于所有情况,而深入的思考系统设计的局限性所在,往往是优化之道、破旧立新的机会。
论文链接 https://www.usenix.org/system/files/conference/nsdi15/nsdi15-paper-ousterhout.pdf https://www.usenix.org/system/files/conference/hotos15/hotos15-paper-mcsherry.pdf
总结
为期三天的 OSDI,我们见证了全世界最优秀的系统设计研究人员思维的闪光,独特而深邃的思考。而于我而言,更重要的是有一个机会能跟这些有趣的大脑进行充分的交流和思维的激荡。在会场上,我也见到了很多当年在MSRA系统网络组一起实习的朋友们,看到这么多志同道合的小伙伴都能在自己喜欢的领域做科研,探寻系统设计的真谛,我感到无比欢喜。
系统研究是最兼容并包的领域,我们一直在关注最新的应用与硬件,思考系统设计领域的创新,解决最重要的问题。系统设计的源泉来自于计算机行业的发展,而每一个优雅的系统设计,又很快应用到计算机产业中,带来深远的影响。期待下一次与 OSDI 的相聚!